3.1 传统RAG的演化过程¶
学习目标¶
-
掌握基础RAG的实施过程和缺点
-
掌握高级RAG的实施过程和缺点
-
掌握模块化RAG的实施过程和缺点
一、基础RAG(Naive RAG)¶
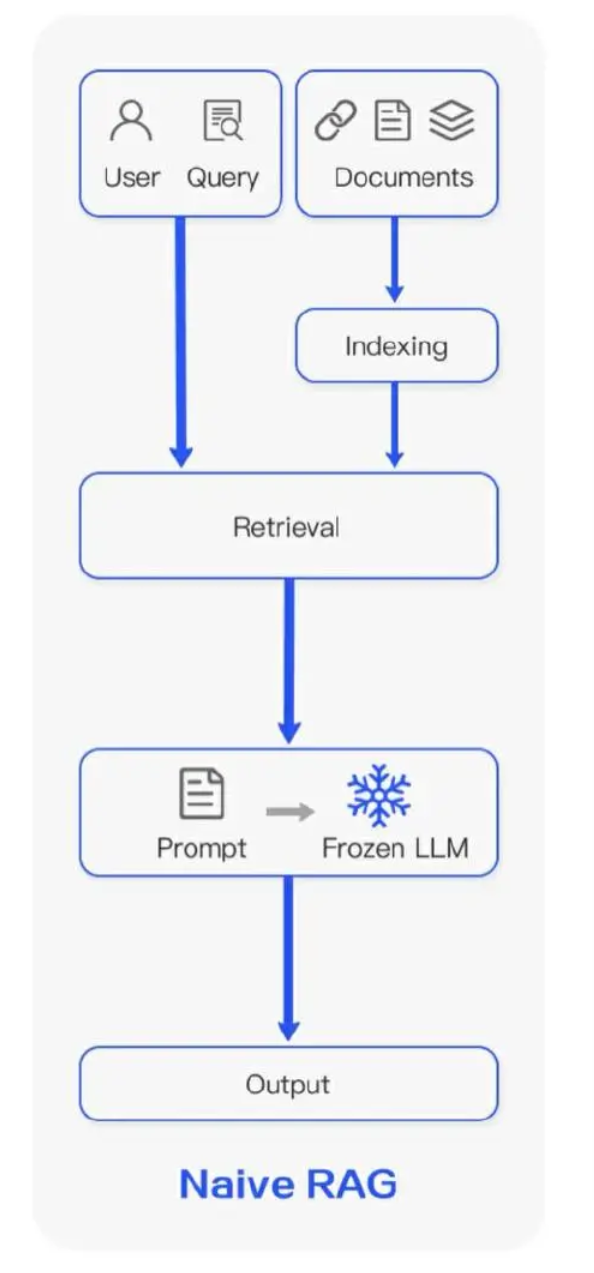
1 实施过程¶
1.1 构建知识库:¶
收集相关文档,对文档进行预处理(清洗、格式化)将文档分块(chunking)使用嵌入模型将文档块转换为向量,将向量存储在向量数据库(如faiss、milvus、chromeDB)。
1.2 检索阶段¶
接收用户问题(query)使用与文档相同的嵌入模型将query转换为向量。在向量数据库中执行k近邻搜索(k-NN)返回与query向量最相似的top-k个文档块。
1.3 生成阶段¶
将检索到的文档块与原始query拼接,形成提示(prompt):"基于【参考信息】回答【用户问题】:\n【用户问题】:query\n【参考信息】:参考信息1,参考信息2......",使用大语言模型基于提供的上下文生成自然语言回答。
2 主要问题¶
2.1 检索不准确¶
检索阶段有时不能准确地找到所需信息。主要是两方面的问题:
- 检索出地块不匹配或者不相关
- 遗漏关键信息
2.2 生成内容呆板¶
生成模型可能过于依赖增强信息,导致输出内容只是重复检索到的文本块或者做简单的变形,没有添加分析或合成的信息。
2.3 生成障碍¶
检索的信息不一定能够很好地与具体任务相结合,有时会导致不连贯的输出;如果检索到多个类似片段,可能会导致语义重复的输出。
二、高级RAG(Advanced RAG)¶
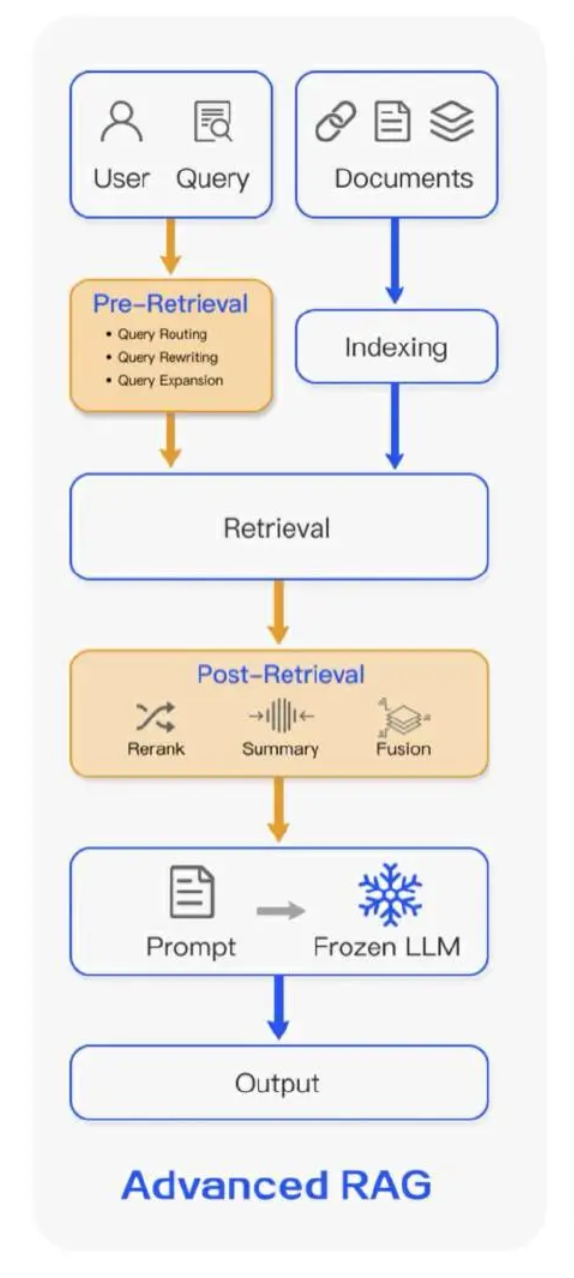
1 实施过程¶
1.1 检索前优化¶
- 用overlapping保证语义完整性
- 添加元数据方便检索(milvus较早认识到这个问题)
- 分层索引(父子切块)
- 查询重写:将用户输入的原始查询根据上下文或通识等进行重新改写
- 查询扩展:通过增加同义词、相关概念等进行扩展,提升检索效果
1.2 检索中优化¶
- 假设文档嵌入:大语言模型先生成一个假设性回答,根据这个假设性回答的嵌入进行检索
- 混合检索:结合使用向量搜索与关键词检索等方式
- 父子检索:先通过子块匹配到精确内容,再通过父块扩展上下文
- 特定领域嵌入微调:通用的嵌入模型往往无法覆盖某些领域的专业术语或特定语义。通过对嵌入模型进行微调,可以增强其在特定领域中的表现
1.3 检索后优化¶
- 重排序
- 提示压缩:通过删除冗余信息、合并相关内容、突出关键信息等方式来压缩提示,为生成模型提供更简洁、更相关的输入。
- 上下文重构:通过将检索到的多个文本片段整合成一个文本块,减少重复或冲突。
- 内容过滤:根据特定规则,过滤掉与查询无关的内容
2 主要问题¶
2.1 检索过程缺少灵活性¶
所有难度和类型的问题都通过一个固定方式检索,不利于处理多种类型的问题
- 问题不属于RAG范围,可以大模型直接回答
- 根据用户的提问,可以自主判定具体检索方式,不必所有检索方式同时使用。
- 根据系统回复的质量,有可能需要二次检索
2.2 部署过程缺少灵活性¶
只能一次性部署整个复杂系统,无法根据特定业务场景灵活部署,降低系统复杂度
三、模块化RAG(Modular RAG)¶
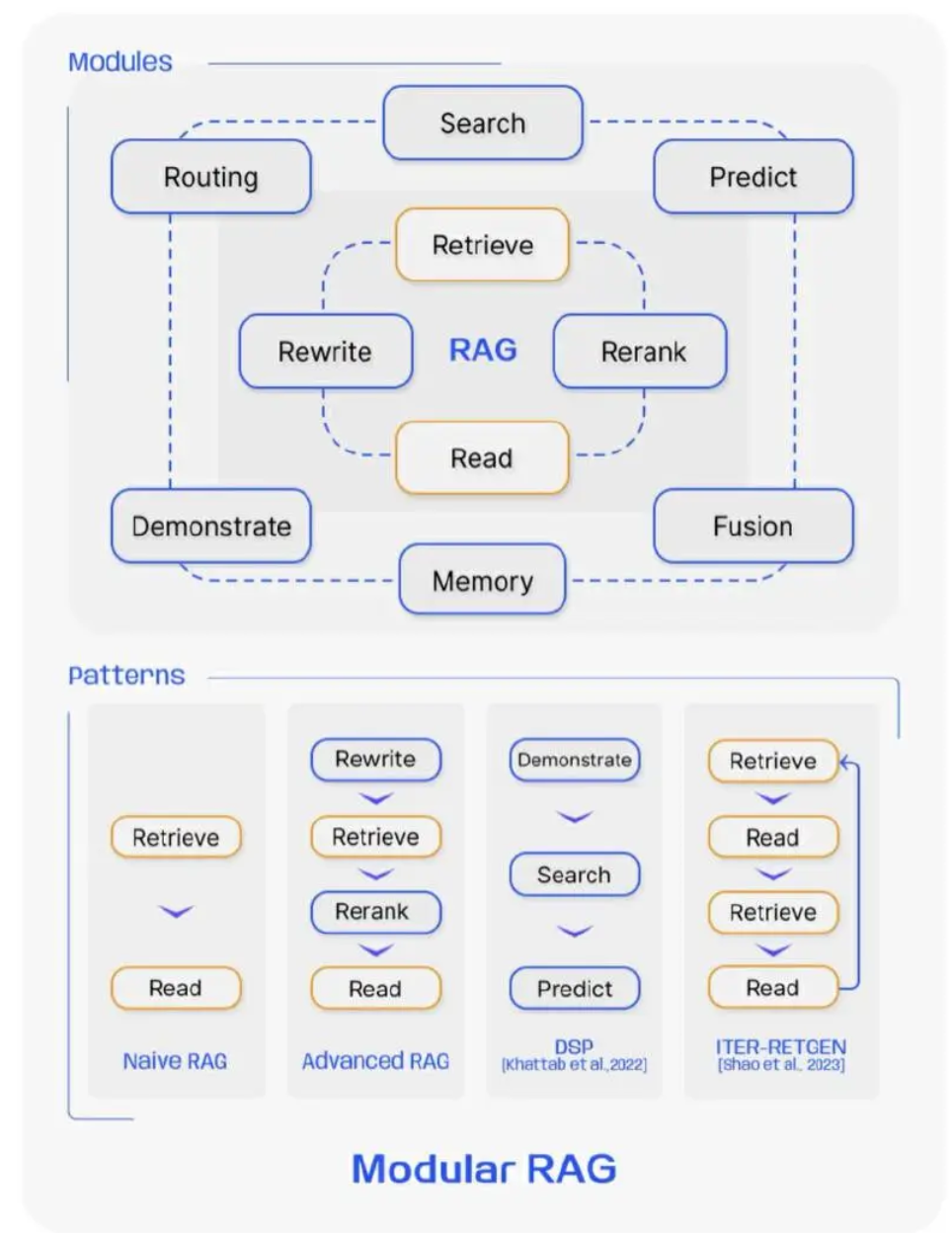
1 核心改进¶
Modular RAG 与 Advanced RAG 的最大区别,是多出了一个编排模块(Orchestration),它通过灵活地路由、调度、知识引导与推理路径动态地决定处理流程,提升整个系统在复杂场景下的适应性和处理能力,其中:
- 路由是编排流程中的关键步骤,它的主要功能是收到用户查询后,根据查询的特点和上下文,选择最合适的流程,例如:问题是否可以直接由大模型回答,是否需要检索数据库,是否多步推理的复杂问题
- 调度是管理查询的执行顺序,并且动态调整检索和生成步骤。例如:判断是否需要补充检索和二次检索等
- 知识引导是结合知识图谱和推理路径来增强处理过程
2 主要问题¶
2.1 多跳问题效果不好¶
虽然Modular RAG通过推理路径有了一定的多跳处理能力,但整体准确率并不高,多跳问题在专业领域出现概率较高,如:类风湿的常用治疗方法引起的并发症如何解决?鲁花集团的竞争对手最近获得了哪些专利?《潜伏》的男一号最近有什么新作品?
2.2 无法形成全局理解¶
无法做到对多个(数百到数万)文档做全局理解或概括,难以回答这样的问题:近五年AI研究趋势(数千个文档)、中国移动福州分公司2024年主要工作亮点(全年的工作记录,分散在几百个文档中)。