4.1 新型RAG¶
学习目标¶
- 掌握基于知识图谱的RAG的实施过程和缺点
- 掌握基于智能体的RAG的实施过程
一、基于知识图谱的RAG(Graph RAG)¶
1 实施过程¶
基于知识图谱的RAG主要依赖知识图谱和社区检测形成全局理解和多跳处理能力。主要产品有GraphRAG,LightRAG等。
1.1 文本分块¶
1.2 图谱抽取¶
使用大语言模型抽取文本块中的实体和关系
1.3 实体和关系的描述与向量化¶
将所有的实体和关系用一段文本描述出来,并且向量化,作为后续检索的知识
1.4 社区检测与描述¶
使用Louvain或Leiden等算法从知识图谱中抽取出社区,并使用大模型做出描述
2 主要问题¶
2.1 成本太高¶
因为需要大模型抽取实体和关系,对大模型的质量有很高的要求,想要准确只能使用高质量大模型;需要使用大模型对所有实体和关系做出描述,产生大量调用,算力和时间的成本都非常高。
2.2 无法给出综合性报告¶
只能够回答特定问题,无法做综合性分析,给出专业的工作报告
二、智能体RAG(Agentic RAG)¶
一般来说,RAG通常作为智能体的子模块,但是也可以逆向思维,让智能体为RAG服务。这类产品主要有,deepsearch、deepresearch等。
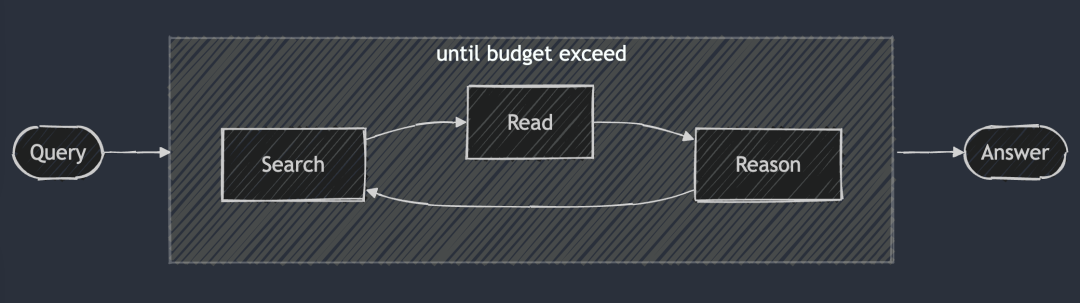
智能体RAG的主要思路是构建一个基于“搜索-阅读-推理”的循环,可用于生成非常复杂的研究报告。主要改进点如下:
- 问题规划与拆分:将复杂问题拆分成多个子问题,并规划解决方案
- 反思与优化:分析上一步的结果,如果不理想,改进和调整检索策略
- 工具集成:利用agent调用工具的能力,整合使用不同的数据源和外部工具
- 跨模态信息整合:文本、图像、视频、音频、结构化数据库等
- 模块化架构:可以自由地使用单agent或多agent协作等架构方式